Kan «on-prem» kunstig intelligens bli løsningen på personvernfloka?
Det er 28. januar, den internasjonale personverndagen. I år blir den overskygget av lanseringen av DeepSeeks siste KI-modell.
Appen ligger på app-listetopper verden over, på tross av klare advarsler om at all data sendes til Kina, og i alle tilfeller kan brukes til videre analyse og trening av modellen.
Personvernutfordringene er store, men det kan se ut til at hype trumfer vårt ønske om å verne om egne opplysninger.
Det kan høres ut som et paradoks all den tid de aller fleste organisasjoner vegrer seg mot å ta i bruk avanserte KI-modeller- men det er det ikke. Organisasjoner har et helt annet ansvar og en helt annen mulighet til å ta stilling til kompliserte utfordringer enn individer.
Så- hvordan kan organisasjoner på en ansvarlig måte levere gevinstene som gjør at oss som individer kaster all forsiktighet i vinden? Kanskje kan nettopp DeepSeek være en del av løsningen!
Ved å dramatisk effektivisere implementeringen av klasseledende kunstig intelligens, og så gjøre fremgangsmåten «open source», ligger det å kjøre slike klasseledende systemer lokalt nå innenfor rekkevidde.
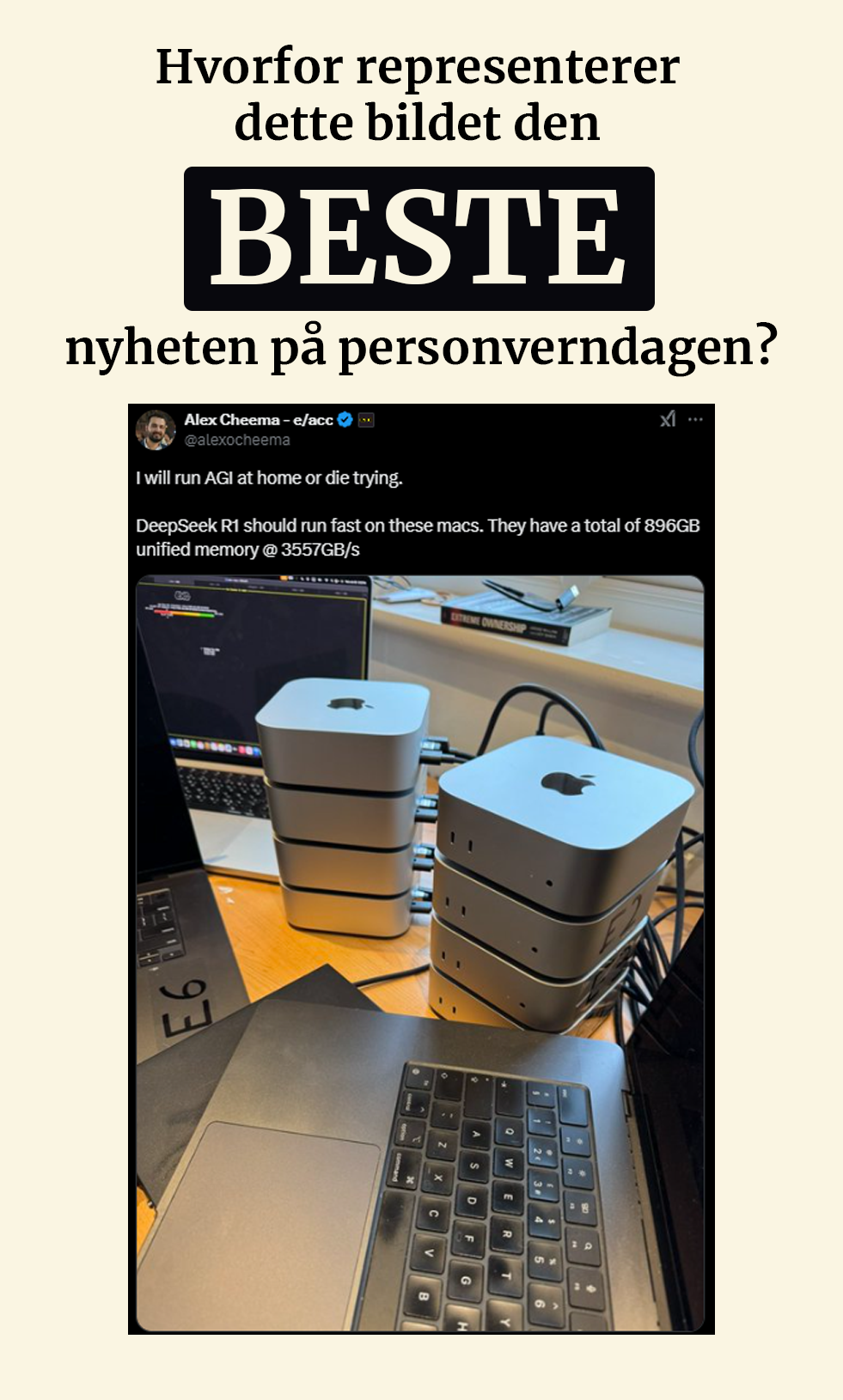
På bildet har Twitter-brukeren Alex Cheema linket sammen totalt 9 macer for å få tilstrekkelig minne til å kjøre DeepSeek R-1. Det er langt fra billig, men at å kjøre en slik modell i det hele tatt er mulig med produkter du kan kjøpe i butikken, er en milepæl!
På denne måten kan en unngå personvern- og sikkerhetsproblematikken knyttet til å sende data ut av organisasjonen, som synes å være den største bremseklossen i dag. Det gjenstår mange utfordringer knyttet til ansvarlig og oversiktlig forvaltning og bruk, men en har kommet et stort skritt på vei!
DeepSeek har, ved å gjøre sin modell både ressurseffektiv og open source, tatt et slag for personvernet langt større en alle andre aktører i KI-kappløpet til sammen. Det burde feires på personverndagen!